
DXOMARK’s Decodes series aims to explain concepts or dispel myths related to technology, particularly in smartphones and other consumer electronics. In this edition, we address the current buzz around artificial intelligence and briefly look at one way that AI is being used in smartphone cameras. We’ll continue to explore other ways in which AI is used in smartphone cameras and image quality assessment in future articles.
Smartphone photography has always had an element of magic about it. We just point and tap our devices in the hopes of capturing a moment or the scenery, no matter how challenging the situation might be. Smartphone cameras are now very sophisticated in the way they can make almost any image or video come out with correct exposure, good details, and great color, helping to overcome the compact device’s optical limitations.
Recently, we saw the importance that smartphone makers are placing on using artificial intelligence in the latest flagships to improve the user experience, particularly the image-taking experience. We saw some of the latest AI camera technologies with the release of Samsung’s Galaxy S24 Ultra, for example, which emphasized a range of AI photography tools that can guide the image-taking process from “preview to post,” including editing capabilities that allow users to resize or move objects or subjects after capturing the image. The latest Google Pixel phones also use AI technologies that allow users to reimagine or fix their photos with features like “Best Take” or “Magic Eraser,” which blend or change elements such as facial expressions, as well as erase unwanted elements from a photo.
But while smartphones put a camera in everybody’s hands, most smartphone users are not photographers, and many devices do not even offer options to adjust certain photographic parameters, in many cases thanks to AI. As AI makes its way into many aspects of our lives, let’s briefly explore what is AI and how it is being applied to smartphone cameras.
What do we mean by AI?
AI is a fast-developing field of computer science that offers the possibility of solving many problems by perceiving, learning, and reasoning, to intelligently search through many possible solutions. AI has given computer systems the ability to make decisions and to take action on their own depending on their environment and the tasks they need to achieve. With AI, computer systems are performing tasks that normally would have required some degree of human intelligence, for example, from driving a car to taking pictures. It’s no wonder that companies worldwide are using AI to improve their products, services, and the user experience.
We often hear the terms Artificial Intelligence, machine learning and deep learning bandied about interchangeably. But the three terms have some distinctive differences in how they process data.
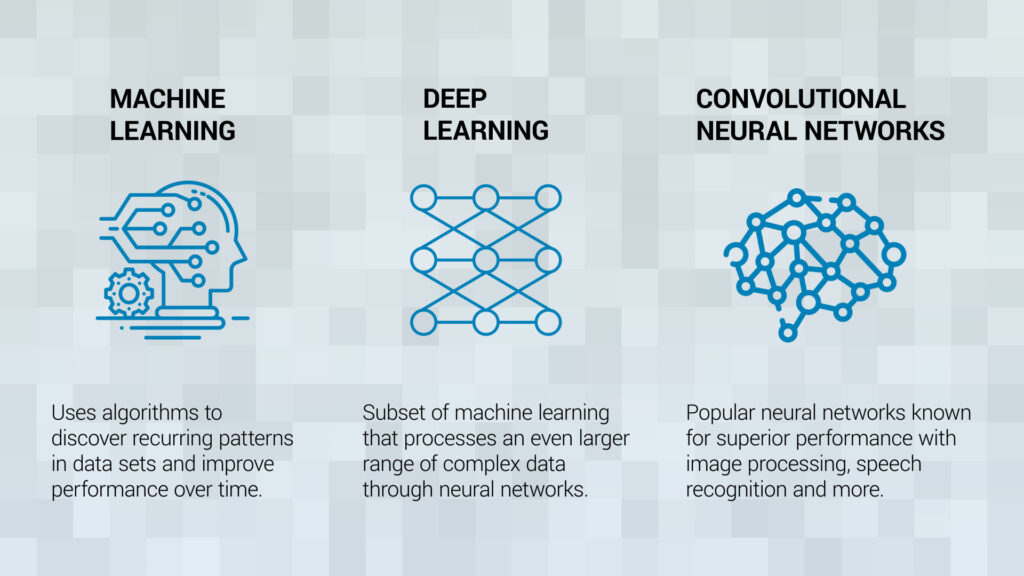
Artificial Intelligence is a general term to describe the ability of a computer or robot to make decisions autonomously. Within AI is a subfield called machine learning, which contains the algorithms that integrate information from empirical data. The programmer, after coding the algorithm, executes it on a set of data that is used for “training”. The algorithm will look for patterns in the data that allow it to make predictions on a given task. Once new data comes in, the algorithm can search for the same patterns and make the same kind of predictions on the new data. It is the algorithms that learn to adapt to the new data.
A subset of machine learning is called deep learning, which processes an even larger range of complex data in a more sophisticated way, through multiple layers called neural networks to achieve even more precise results and predictions.
Deep learning-based models, for example, are widely used now in image segmentation on X-rays for medical applications, in satellite imaging, and in self-driving cars.
Smartphone photography is also benefitting from deep learning models as cameras are programmed to learn how to produce and create a perfect image.
How AI is used in smartphone photography
You might not realize it, but even before you press the shutter button on your smartphone to take a photo or video, your personal pocket photographer has already begun working on identifying the scene and in some cases differentiating the objects and setting the parameters to be ready to produce an image that will hopefully be pleasing to you.
Smartphone photography is a good example of AI at work because the images are already a result of computations that rely on certain AI elements such as computer vision and algorithms to capture and process images.
In contrast, a traditional DSLR camera provides a photographer with a wide range of parameters for creative image-taking. The way these parameters are set depends on:
–identifying the scene (portrait, natural scene, food, etc.) that is to be photographed and the semantic content of the scene, meaning what should the viewer focus on in the image
–the properties of the scene such as the amount of light, distance to the target, etc
But most smartphone cameras do not even offer the option to adjust these parameters.
Scene detection
The ability of a machine to learn depends on the quality of the data it processes. Using computer-vision algorithms, which in itself is a form of AI, a smartphone camera needs to be able to correctly identify the scene by extracting information and insights from the images and videos in order to adapt its treatment.
The following examples are simple segmentations, in which the object is separated from the background and categorized.

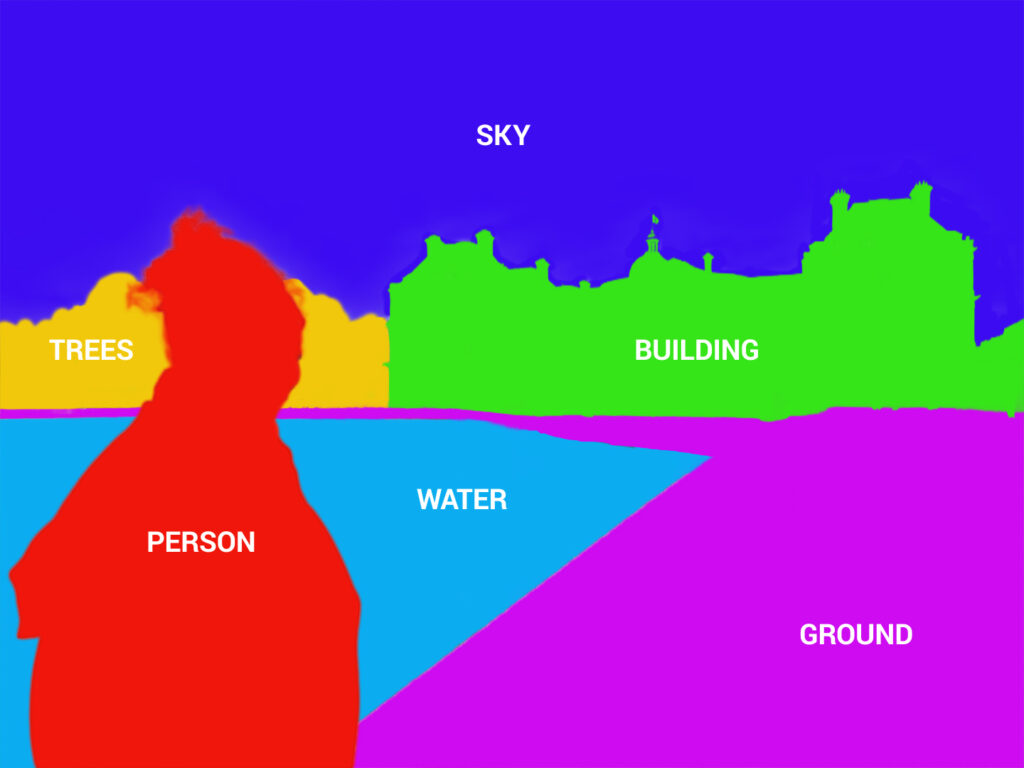
What allows the computer or device to extract this information is called a neural network. With neural networks, computers can then distinguish and recognize images in the same way that humans do.
There are many different types of neural networks, but the main machine-learning model used for images is known as a Convolutional Neural Network (CNN), which puts an image through filters or layers that activate certain features from the photo. This then allows the scene and objects in the scene to be identified and classified. CNNs are used for semantic segmentation of an image, in which each pixel in an image is categorized into a class or object.
Semantic segmentation and image labeling, however, are the most challenging tasks for computer vision.
For cameras to be able to learn to “see” scenes and objects like humans do depends on extensive databases of meticulously annotated and labeled images. Image labeling is still a task that requires human input, and many companies create and sell massive databases of labeled photos that are then used to create machine learning models that can be adapted for a wide range of products and specific applications.
The technology has advanced very quickly, and some chipmakers are already incorporating semantic segmentation into their latest chips so that the camera is aware and “understands” what it is seeing as it takes the photo or video to optimize it. This is known as real-time semantic segmentation or content-aware image processing. Many of these technologies are thanks to improved processing power from the chipsets, which are now integrating many of these AI technologies to optimize photo- and video-taking. By having the capability to separate the regions of an image in real time, certain types of objects in the image can be optimized for qualities such as texture and color. We’ll take a closer look at all the other ways that AI plays a role in image processing in another article.


Now let’s take a look at a real-life example of AI at work in a smartphone camera. The example below reveals how the camera is making decisions and taking action on its own based on what it is identified in the scene. You’ll see how the camera adjusts the image as it goes from identifying the scene (is it a natural scene or portrait) to detecting a face and then adjusting the parameters to provide a correct exposure for a portrait — the target (the face).



In Photo 1 on the left, the camera identifies a natural landscape scene and exposes it, but at Photo 2, when the subject turns around, we see that the camera still has not fully identified the face, but by Photo 3, the camera has identified a face in the scene and has taken action to focus on it and expose it properly at the expense of the background exposure. In addition to the changed exposure of the background as well as the face when comparing Photo 3 with Photo 1, we also see that the subject’s white T-shirt has lost much of its detail and shading.
While Photo 3 is not ideal in terms of image quality, we can clearly see the camera’s decision-making process to prioritize the portrait for exposure.
Conclusion
As more manufacturers incorporate the “magic” of AI into their devices, particularly in their camera technology to optimize photos and videos, software tuning becomes more important to get the most out of these AI capabilities.
Through machine learning, smartphone cameras are being trained to identify the scenes more quickly and more accurately in order to adapt the image treatment. Through deep learning and its use of neural networks, particularly the image-specific CNN, smartphone cameras are not only taking photos, but they are also making choices about the parameters once reserved for the photographer.
AI is helping to turn the smartphone camera into the photographer.
We hope this gives you a basic understanding of how AI is already at work in your smartphone camera. We will continue to explore how AI affects other areas of the smartphone experience in future articles. Keep checking dxomark.com for more Decodes topics.